Datamining und ML als wesentliche KI-Teilgebiete
Auswerten von großen Daten(-Mengen) im Ingenieurwesen - gestern und heute
Seit jeher werden im Ingenieurwesen Daten verarbeitet - insbesondere in Entwicklung und Konstruktion und in der Betriebsüberwachung von Verfahren/Prozessen aller Art.
Die Qualität von neu entwickelten Produkten sowie Qualitätsbeständigkeit während der Lebensdauer von Produkten werden mittels Untersuchungen und Tests überwacht. Die dabei ermittelten Daten sind auszuwerten, um Bewertungsergebnisse zu einem Urteil zusammenfassen zu können.
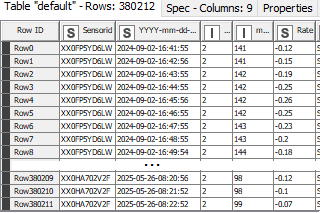
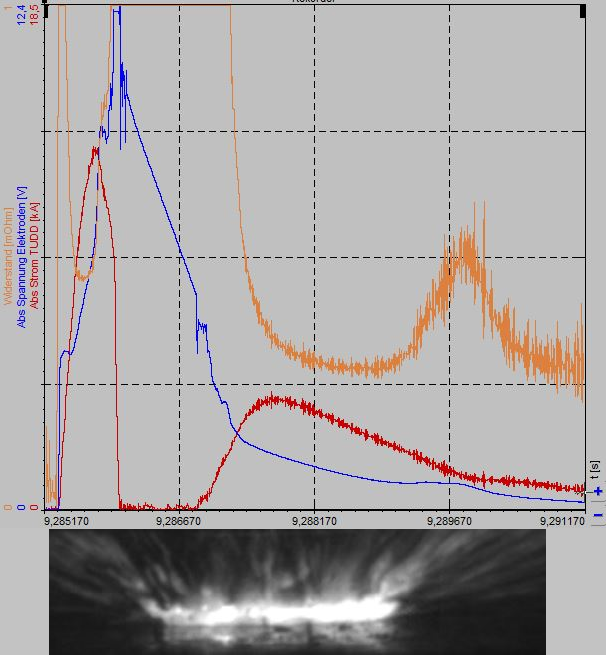
Bei der Überwachung von Fertigungsverfahren und anderer technischer Prozesse fallen ununterbrochen über 24/7 große Mengen an Daten an, die zu bewerten sind, um insbesondere eine konstant hohe Produktqualität zu gewährleisten.
Seit jeher werden im Ingenieurwesen Daten verarbeitet - insbesondere in Entwicklung und Konstruktion und in der Betriebsüberwachung von Verfahren/Prozessen aller Art.
Die Qualität von neu entwickelten Produkten sowie Qualitätsbeständigkeit während der Lebensdauer von Produkten werden mittels Untersuchungen und Tests überwacht. Die dabei ermittelten Daten sind auszuwerten, um Bewertungsergebnisse zu einem Urteil zusammenfassen zu können.
Bei der Überwachung von Fertigungsverfahren und anderer technischer Prozesse fallen ununterbrochen über 24/7 große Mengen an Daten an, die zu bewerten sind, um insbesondere eine konstant hohe Produktqualität zu gewährleisten.
Meine Kernkompetenz:
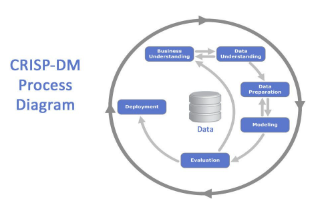
Datamining und Maschinelles Lernen
Erstellen und Projektbetreuung
von Anwendungen
der Künstlichen Intelligenz


Datamining/ML - in der heutigen Zeit einfach unverzichtbar!
Datamining/ML ergänzt oder ersetzt gar die traditionellen Methoden der Ingenieurwissenschaften: